Ocasionalmente, um problema vai pousar sobre a mesa que está um pouco fora do comum. Algo que você não tem uma resposta fácil. Você vai para o seu cérebro e o seu cérebro não retorna nada.
Estes problemas não podem ser resolvidos com um pouco de pesquisa de palavras-chave e técnicas básicas de configuração. Estes são os tipos de técnicas de SEO problemas onde a toca do coelho vai fundo.
A própria natureza dessas situações desafia uma lista de verificação, mas é útil ter uma pela mesma razão, nós temos de nos aviões: até mesmo o melhor de nós pode e vai se esqueça de coisas, e uma lista de verificação provvide você com lugares para cavar.
Gosto de alguns exemplos de estranho SEO problemas? Aqui estão quatro exemplos para meditar mais, enquanto você lê. Nós responderemos ao final.
1. Por que não era do Google mostrando, de 5 estrelas, marcação em páginas de produto?
- Páginas tinham servidor prestados a marcação de produto e eles também tinham Feefo a marcação de produto, incluindo classificações de ser ligado do lado do cliente.
- O Feefo classificações trecho foi processado com êxito na Obtenção & Render, além de móveis ferramenta amigável.
- Quando você colocar o processado DOM para a ferramenta de teste de dados estruturados, ambas as peças de dados estruturados apareceu sem erros.
2. Por que não Bing display de 5 estrelas marcação na análise de páginas que o Google faria?
- As páginas de revisão do cliente & concorrentes, todos tinham a classificação de rich snippets no Google.
- Todos os concorrentes tinham de classificação de rich snippets no Bing; no entanto, o cliente não.
- A revisão de páginas tinha validando corretamente classificações de esquema no Google, ferramenta de teste de dados estruturados, mas não no Bing.
3. Por que foram páginas recebendo indexados com uma marca de índice?
- Páginas com um servidor-lado-processado de não-marca de índice na cabeça estavam sendo indexado pelo Google através de um grande modelo para um cliente.
4. Por que qualquer página em um site de retorno de um 302 cerca de 20-50% do tempo, mas apenas para os rastreadores?
- Um site foi aleatoriamente jogando 302 erros.
- Isto nunca aconteceu no navegador e apenas em rastreadores.
- Agente de usuário não fez nenhuma diferença; localização ou os cookies também não fez nenhuma diferença.
Finalmente, uma nota rápida. É inteiramente possível que alguns desta lista de verificação não se aplicam a cada cenário. Que tudo bem. Ele é destinado a ser um processo para tudo que você poderia verificar, nem tudo o que você deve verificar.
O checklist completo

Você pode baixar o modelo de lista de verificação aqui (é só fazer uma cópia do Google Folha):
Obter a lista de verificação de folha de cálculo
A pré-lista de verificação de verificação
Realmente importa?
Esse problema afeta apenas uma pequena quantidade de tráfego? É apenas em um punhado de páginas e você já tem uma lista grande de outras ações que vão ajudar o site? Você provavelmente terá que é só soltá-lo.
Eu sei, eu odeio isso também. Eu também quero ser direito e cavar essas coisas. Mas, dentro de seis meses, quando você resolveu vinte complexo de SEO coelho buracos e seu site ficou plana, porque você não re-escrever as tags de título, você ainda vai ser demitido.
Mas espero que esse não é o caso, caso em que, diante!
Onde você está vendo o problema?
Não queremos perder muito tempo. Você já ouviu falar deste maravilhoso dizendo?: “Se você ouvir os cascos, ele provavelmente não será uma zebra.”
O processo que está prestes a passar é bastante envolvidos e é inteiramente a seu critério se você quiser ir em frente. Apenas certifique-se de que você não está com vista algo óbvio que iria resolver o seu problema. Aqui estão alguns problemas comuns com que me deparei que foram principalmente de cavalos.
Fatores que tornam mais provável que você tem um problema mais complexo, que exige que não a sua depuração sapatos:
- Um site que tem um monte de JavaScript do lado do cliente.
- Maiores, mais antigos sites com mais de legado.
- O problema está relacionado a uma nova propriedade do Google ou recurso onde há menos conhecimento da comunidade.
1. Comece por escolher alguns exemplos de páginas.
Escolher um par de páginas de exemplo para trabalhar, aqueles que apresentam qualquer problema que você está vendo. Não, este não ser representativas, mas nós vamos voltar daqui a pouco.
É claro que, se ela afeta apenas um pequeno número de páginas, em seguida, ele realmente pode ser representante, caso em que somos bons. Definitivamente importa, certo? Você não pode simplesmente pular o passo acima? OK, legal, vamos seguir em frente.
2. O Google pode rastrear a página de uma só vez?
Primeiro estamos a verificar se o Googlebot tem acesso à página, o que nós vamos definir um código de status 200.
Vamos verificar em quatro maneiras diferentes para expor os problemas comuns:
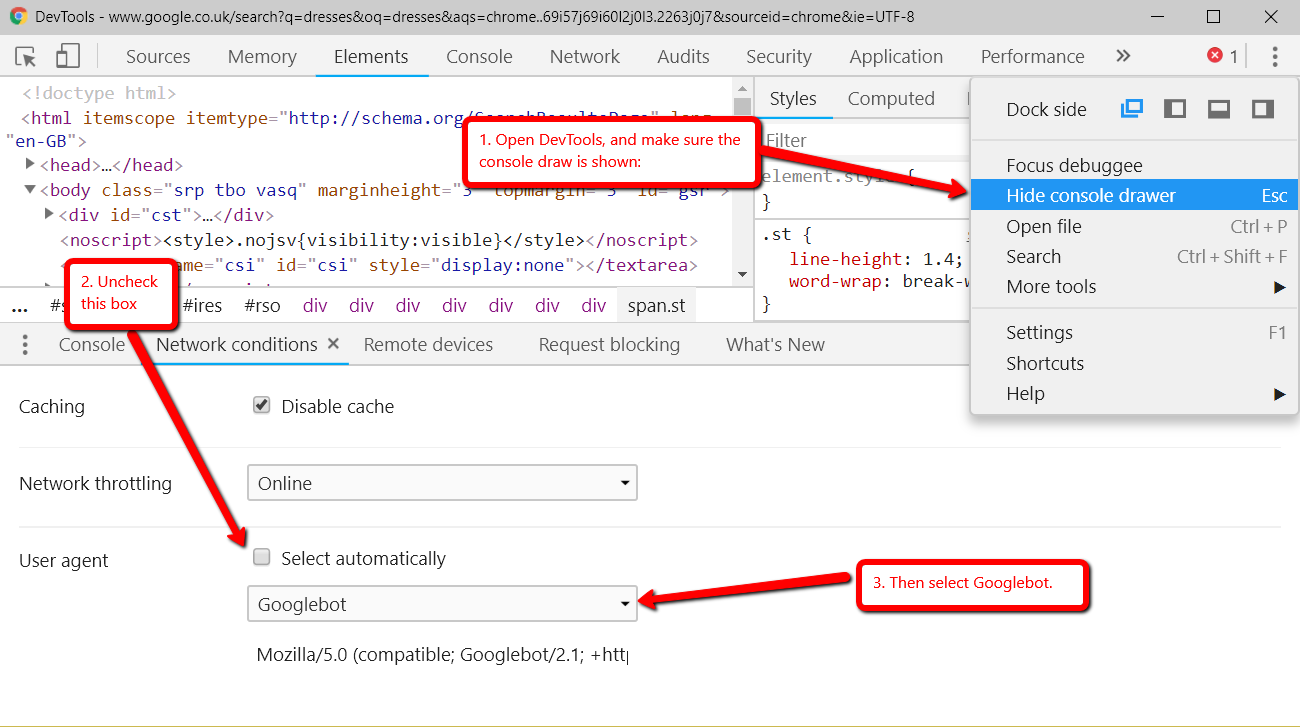
Devemos agora ter uma ideia se é ou não o Googlebot está lutando para obter a página de uma vez.
Temos encontrado problemas ainda?
Se podemos re-criar uma falha de rastreamento com uma simples seleção acima e, em seguida, é provável que o Googlebot é, provavelmente, falhando de forma consistente, para buscar a nossa página e é, normalmente, uma dessas razões básicas.
Mas pode não ser. Muitos problemas são inconsistentes devido à natureza da tecnologia. 😉
3. Estamos dizendo ao Google duas coisas diferentes?
Ao lado: o Google pode encontrar a página, mas estamos a confundir dizendo que duas coisas diferentes?
Isso é mais comumente visto, na minha experiência, porque alguém tem bagunçou a indexação directivas.
Por indexação “directivas” estou me referindo a qualquer tag que define o índice correto de estado ou uma página de índice que deve classificação. Aqui está uma lista não exaustiva:
- Sem índice
- Canonical
- Móvel alternativo tags
- AMP alternativo tags
Um exemplo de prestação de mensagens misturadas seria:
- Não-indexação de Uma página
- Página B paramentos para A página A
Ou:
- A página tem Um canônica em um cabeçalho para um com um parâmetro
- A página tem Um canônica no corpo de Um sem um parâmetro
Se estamos fornecendo mensagens misturadas, então não é clara a forma como a Google irá responder. É uma ótima maneira para começar a ver resultados estranhos.
Bons lugares para verificar a indexação directivas enumeradas acima são:
- Sitemap
- Exemplo: Móveis alternativo tags podem sentar-se em um sitemap
- Cabeçalhos HTTP
- Exemplo: Canónico e meta robots podem ser definidas em cabeçalhos.
- HTML cabeça
- Este é o lugar onde provavelmente você está procurando, você precisará de um presente para uma comparação.
- JavaScript-renderizados vs hard-coded directivas
- Você pode ser a definição de uma coisa no código fonte da página e, em seguida, renderização outro com JavaScript, por exemplo, você gostaria de ver algo diferente no código fonte HTML da processado DOM.
- Pesquisa do Google configurações do Console
- Há de Pesquisa de definições da Consola para ignorar parâmetros e do país de localização que podem conflitar com a indexação de etiquetas na página.
Uma rápida lado prestados DOM
Esta página tem um monte de menções a prestação do DOM (18, se você estiver curioso). Desde que tivemos o nosso primeiro, aqui está uma rápida retrospectiva sobre o que é.
Quando você carrega uma página da web, o primeiro pedido é o HTML. Isso é o que você vê no código fonte HTML (clique com o botão direito do mouse em uma página da web e clique em Ver código-Fonte).
Este é antes de JavaScript tem feito nada para a página. Este não ser um negócio tão grande, mas agora muitos sites dependem de JavaScript que a maioria das pessoas bastante razoável de não confiar na inicial HTML.
Prestados DOM ” é o termo técnico para uma página, quando todas as JavaScript foi processado e todas as página alterações feitas. Você pode ver isso no Dev Tools.
No google Chrome você pode obter isso clicando com o botão direito e bater inspecionar elemento (ou Ctrl + Shift + I). Os Elementos guia irá mostrar o DOM, como ele está sendo processado. Quando ele pára de cintilação e mudança, então você tem o processado DOM! 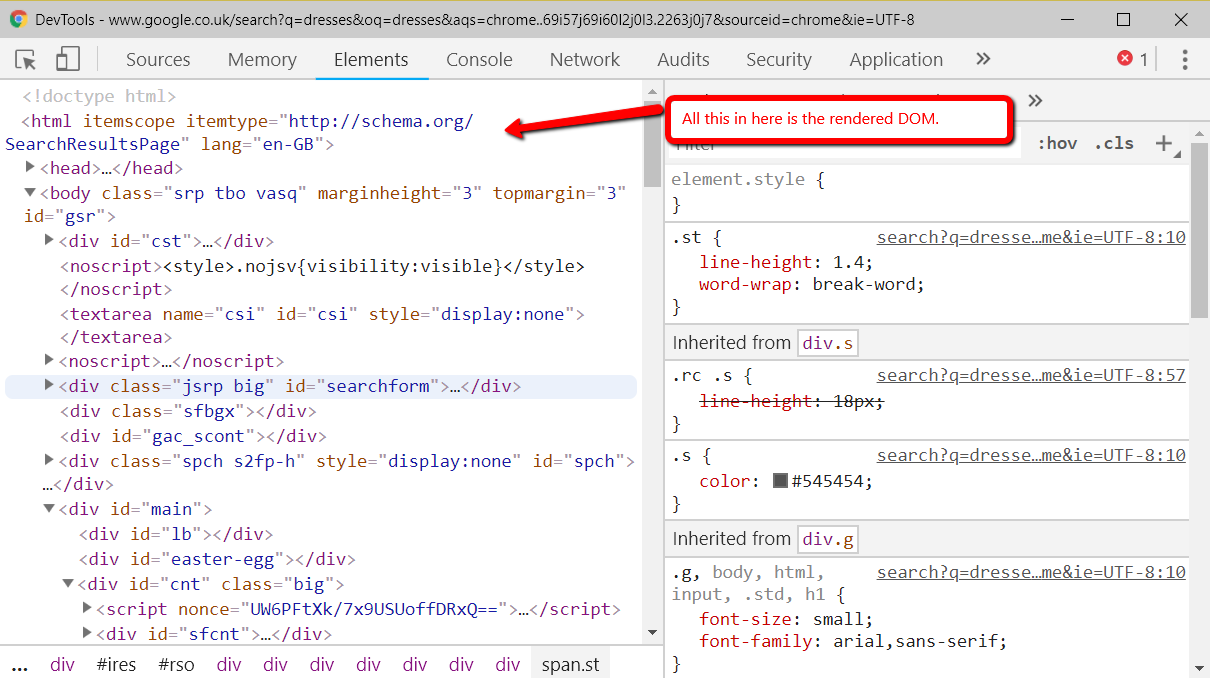
4. O Google pode rastrear a página de forma consistente?
Para ver o que o Google está vendo, vamos precisar obter arquivos de log. Neste ponto, podemos ver como ele está acessando a página.
Observação: Trabalhar com logs é uma postagem inteira em si mesma. Eu escrevi um guia para análise de log com o BigQuery, eu também recomendo experimentar Gritando Sapo Analisador de Log, que tem feito um grande trabalho de manipulação de um monte de complexidade em torno de logs.
Quando estamos olhando para rastrear, existem três útil verifica que nós podemos fazer:
Temos encontrado problemas ainda?
Se o Google não está ficando 200s de forma consistente em nossos arquivos de log, mas podemos acessar a página bem quando tentamos, em seguida, há claramente ainda algumas diferenças entre o Googlebot e de nós mesmos. O que talvez essas diferenças?
Isto significa que:
- Se o nosso website está fazendo inteligente bot de bloqueio, ele pode ser capaz de diferenciar entre nós e o Googlebot.
- Porque o Googlebot vai colocar mais pressão em nossos servidores da web, ele pode se comportar de forma diferente. Quando os sites tiverem um monte de bots ou visitantes de uma só vez, podem tomar algumas ações para ajudar a manter o site online. Eles podem se transformar em mais computadores para alimentar o site (isso é chamado de escala), eles também podem tentar avaliá-limite de usuários que estejam solicitando muitas páginas, ou servir versões reduzidas das páginas.
- Servidores de executar tarefas periodicamente; por exemplo, um listagens site possa executar uma tarefa diária, às 01:00 para limpar todas as velhas listas, que podem afetar o desempenho do servidor.
Trabalhar para fora o que está acontecendo com esses efeitos periódicos vai ser complicado; você provavelmente vai precisar de falar com um back-end developer.
Dependendo do seu nível de habilidade, você pode não saber exatamente onde a liderar a discussão. Uma estrutura útil para uma discussão muitas vezes é para falar sobre como um pedido passa através de sua pilha de tecnologia e, em seguida, olhar para os casos extremos em que discutimos acima.
- O que acontece com os servidores sob carga pesada?
- Quando fazer importantes tarefas agendadas acontecer?
Dois úteis informações para entrar nesta conversa com:
Se o Google pode rastrear a página de forma consistente, em seguida, vamos passar para o nosso próximo passo.
5. O Google ver o que eu posso ver em uma base?
Sabemos que o Google rastrear a página corretamente. O próximo passo é tentar descobrir o que o Google está vendo na página. Se você tem um JavaScript-pesado site provavelmente você já bateu sua cabeça contra esse problema antes, mas mesmo se você não esta ainda pode às vezes ser um problema.
Nós seguimos o mesmo padrão de antes. Primeiro, temos que tentar recriá-la de uma vez. As ferramentas a seguir vamos fazer isso:
- Buscar & Render
- Mostra: Prestados DOM em uma imagem, mas só retorna o código fonte da página HTML para que você leia.
- Móveis de teste
- Mostra: Prestados DOM e retorna prestados DOM para a leitura.
- Isso não só mostrar-lhe prestados DOM, mas ele também irá controlar qualquer console de erros.
Existe uma diferença entre Buscar & Render, o mobile-friendly ferramenta de teste, e o Googlebot? Não realmente, com exceção dos tempos de espera (que é por isso que nós temos os nossos passos mais adiante!). Veja a análise completa da diferença entre eles, se você estiver interessado.
Uma vez que temos a saída desses, podemos compará-los ao que nós habitualmente vemos no navegador. Eu recomendo usar uma ferramenta como ‘Diff’, o Verificador de comparar os dois.
Temos encontrado problemas ainda?
Se encontrar diferenças significativas neste ponto, então, na minha experiência, é normalmente a partir de JavaScript ou os cookies
Por quê?
- O Googlebot rastreia com cookies limpo entre solicitações de página
- O Googlebot compõe com o Chrome 41, que não oferece suporte a todas as moderno JavaScript.
Podemos isolar cada uma destas por:
- Carregando a página sem cookies. Isso pode ser feito simplesmente por carregar a página, com uma nova sessão de navegação anónima e comparar os prestados DOM aqui contra o processado DOM em nosso ordinária do navegador.
- Use o celular ferramenta de teste para ver a página com o Chrome 41 e comparar com a prestação do DOM que nós normalmente a ver com Inspecionar Elemento.
Mas, novamente, podemos compará-los usando algo como ‘Diff’, o Verificador, o que nos permitirá detectar quaisquer diferenças. Você pode querer usar um HTML formatador de linha de ajuda-los melhor.
Também podemos ver os erros de JavaScript jogados utilizando o Mobile-Friendly Ferramenta de Testes, o que pode revelar-se particularmente útil se você está confiante em sua JavaScript.
Se, usando esse conhecimento e essas ferramentas, podemos recriar o bug, então temos algo que pode ser replicado e é mais fácil para nós para entregar para um desenvolvedor, como um bug que será corrigido.
Se estamos vendo que tudo está correto aqui, nós vamos para o próximo passo.
6. O que o Google está realmente vendo?
É possível que o que o Google está vendo é diferente do que nós recriar usando as ferramentas do passo anterior. Por quê? Um casal razões principais:
- Sobrecarregado de servidores pode ter todos os tipos de comportamentos estranhos. Por exemplo, eles podem voltar a 200 códigos, mas talvez com uma página padrão.
- JavaScript é processado separadamente a partir de páginas que estão sendo rastreados e o Googlebot pode gastar menos tempo de renderização de JavaScript do que uma ferramenta de teste.
- Muitas vezes há um monte de armazenamento em cache na criação de páginas da web e isso pode causar problemas.
Nós chegamos até aqui sem falar do tempo! As páginas não recebem rastreado instantaneamente e páginas rastreadas não seja indexado instantaneamente.
Rápida a barra lateral: o Que é cache?
O cache é muitas vezes um problema se você chegar a esta fase. Ao contrário da JS, ele não falou tanto em nossa comunidade, por isso vale a pena alguns mais explicações no caso de você não está familiarizado. O cache é armazenar algo assim que está disponível mais rapidamente da próxima vez.
Quando você solicita uma página da web, um monte de cálculos acontecer para gerar a página. Se você, em seguida, atualizar a página quando foi feito, seria muito desperdício apenas re-executar todos os cálculos mesmos. Em vez disso, os servidores, muitas vezes, salvar a saída e servir-lhe a saída sem re-executar-los. Guardar a saída é chamado de cache.
Por que precisamos saber de uma coisa? Bem, já estamos bem para as plantas daninhas neste ponto e, portanto, é possível que um cache é configurado incorretamente e informações erradas estão sendo devolvidos aos usuários.
Não há muitas boas iniciante recursos de armazenamento em cache que nos aprofundar mais. No entanto, eu encontrei este artigo no cache básico para ser um dos mais amigas. Ele aborda alguns dos tipos básicos de cache muito bem.
Como podemos ver o que o Google está trabalhando, na verdade?
- O Google cache
- Mostra: código-Fonte
- Enquanto isso não irá mostrar-lhe a prestação do DOM, ele está mostrando a você as matérias HTML Googlebot, de fato, vi quando a visitar a página. Será necessário que você verifique isso com JS deficiência; em caso contrário, abrir-lo, o seu navegador irá executar todos os JS versão em cache.
- Pesquisas em sites de conteúdo específico
- Mostra: Um minúsculo fragmento do conteúdo apresentado.
- Ao procurar por uma frase específica em uma página, exemplo: inurl:example.com/url “só JS texto processado”, você pode ver se o Google conseguir índice de um determinado fragmento de conteúdo. Claro, ele só funciona para o texto visível e perde um monte de conteúdo, mas é melhor do que nada!
- Melhor ainda, fazer a mesma coisa com um rank tracker, para ver se ele muda ao longo do tempo.
- Armazenar o real prestados DOM
- Mostra: DOM Prestados
- Alex da DeepCrawl tem escrito sobre como salvar a prestação do DOM do Googlebot. TL;DR versão: Google vai render JS e colocar pontos finais, para que possamos obter a apresentar o JS-renderizados versão de uma página que ele vê. Podemos, em seguida, salvar, examiná-lo e ver o que deu errado.
Temos encontrado problemas ainda?
Novamente, uma vez que descobrimos o problema, é hora de ir e falar com o desenvolvedor. O conselho para essa conversa é idêntico ao último — tudo o que eu disse lá ainda se aplica.
Outro conhecimento que você deve ir para esta conversa armado com: como o Google funciona e onde ele pode lutar. Enquanto o desenvolvedor saber o técnico meandros do seu website e como ele é construído, eles podem não saber muito sobre como o Google funciona. Em conjunto, isso pode ajudar você a alcançar a resposta mais rapidamente.
A fonte óbvia para isso são recursos ou apresentações dadas pela Google. Dos vários recursos que vêm de fora, eu encontrei esses dois, para alguns dos mais úteis para dar idéias para os primeiros princípios:
- Este excelente palestra, Como faz o Google de trabalhar – Paulo Haahr, é preciso ouvir.
- Em sua recente IO conferência, John Mueller & Tom Greenway, fez uma apresentação sobre como o Google processa o JavaScript.
Mas muitas vezes há uma diferença entre as declarações, o Google irá fazer e o que a comunidade SEO vê na prática. Todos os SEO experiências de pessoas incansavelmente realizar, em nosso ramo, também pode ajudar a lançar alguma introspecção. Há muito muitos lista aqui, mas aqui são dois bons exemplos:
- O Google respeita JS paramentos, Por exemplo, Eoghan Henn faz algum bom cavando aqui, o que mostra que o Google respeitando JS paramentos.
- Como é que o Google indexar diferentes JS quadros? – Outro grande exemplo de um lidos experiência com Bartosz Góralewicz no ano passado para investigar como o Google tratados diferentes quadros.
7. Google poderia estar agregando o seu site através de outros?
Se chegamos a este ponto, estamos muito felizes que o nosso site está funcionando perfeitamente. Mas nem todos os problemas podem ser resolvidos apenas em seu site; às vezes você tem que olhar para a vasta paisagem e SERPs em torno dele.
Mais comumente, o que eu estou procurando aqui está:
- Similar/conteúdo duplicado para as páginas que têm o problema.
- Isso pode ser intencional de conteúdo duplicado (e.g. syndicating conteúdo) ou não intencional (concorrentes ” raspando ou acidentalmente indexado de sites).
De qualquer forma, eles são quase sempre encontrados fazendo exata pesquisas no Google. I. e. tomar relativamente parte específica do conteúdo de sua página e procurando-o entre aspas.
Você já encontrou algum problemas ainda?
Se você encontrar um número de outras cópias exatas, então é possível que eles podem estar causando problemas.
A melhor descrição que eu vim acima com para “você já encontrou um problema aqui?” é: você acha que o Google está unindo páginas semelhantes e mostrando apenas uma? E se for, é escolher o errado página?
Este não tem de ser na tradicional pesquisa do Google. Você pode encontrar uma versão dele no Google Trabalhos, o Google Notícias, etc.
Para dar um exemplo, se você for um revendedor, você pode encontrar conteúdo não é ranking porque há uma outra, mais autoritário revendedor, que constantemente posta o mesmo conteúdo em primeiro lugar.
Às vezes, você vai ver isso de forma consistente e de imediato, enquanto outras vezes a agregação pode estar mudando ao longo do tempo. Nesse caso, você vai precisar de um rank tracker para qualquer propriedade do Google que você está trabalhando para vê-lo.
Jon Earnshaw de Pi Datametrics deu uma excelente palestra sobre o último (em torno de suspeitos SERP de fluxo), que é bem vale a pena assistir.
Uma vez que você encontrou o problema, você provavelmente vai precisar experimentar para saber como contorná-la, mas o mais fácil fatores para jogar com, normalmente, são:
- A De-duplicação de conteúdo
- Velocidade de descoberta (você pode melhorar, muitas vezes, colocando-se uma recepção disponível 24 horas feed RSS de todo o novo conteúdo que aparece)
- Redução de sindicação
8. Um resumo de alguns outros prováveis suspeitos
Se você chegou até aqui, então, temos a certeza de que:
- O Google pode, consistentemente, o rastreamento de nossas páginas como se pretende.
- Estamos enviando o Google consistente sinais sobre o estado da nossa página.
- A Google está constantemente a renderização de nossas páginas como esperamos.
- O Google é escolher a página correta de qualquer duplicados que possam existir na web.
E o seu problema ainda não está resolvido?
E é importante?
Bem, atirar.
Sinta-se livre para nos contratar…?
Tanto quanto eu adoraria que este artigo lista todos SEO problema de sempre, que não é muito prático, então, para acabar com este artigo vamos passar por mais duas dicas comuns e princípios, o que realmente não se encaixam em outro lugar antes que as respostas a essas quatro problemas listados no início.
Inválido/mal construídas em HTML
Você e o Googlebot pode estar vendo o mesmo HTML, mas pode ser inválido ou errado. O Googlebot (e qualquer rastreador, para que o assunto) tem para oferecer soluções quando a especificação HTML não é seguido, e aqueles que, por vezes, pode causar um comportamento estranho.
A maneira mais fácil de encontrá-la é por olho-balling prestados DOM de ferramentas ou usando um validador de HTML.
O validador W3C é muito útil, mas irá lançar um monte de erros/avisos de você não importa. O mais próximo que eu posso dar para uma linha de resumo do que aquelas que são úteis é:
- Procure erros
- Ignorar qualquer coisa para fazer com atributos (não aplicar sempre, mas muitas vezes é verdade).
O exemplo clássico é o de quebrar a cabeça.
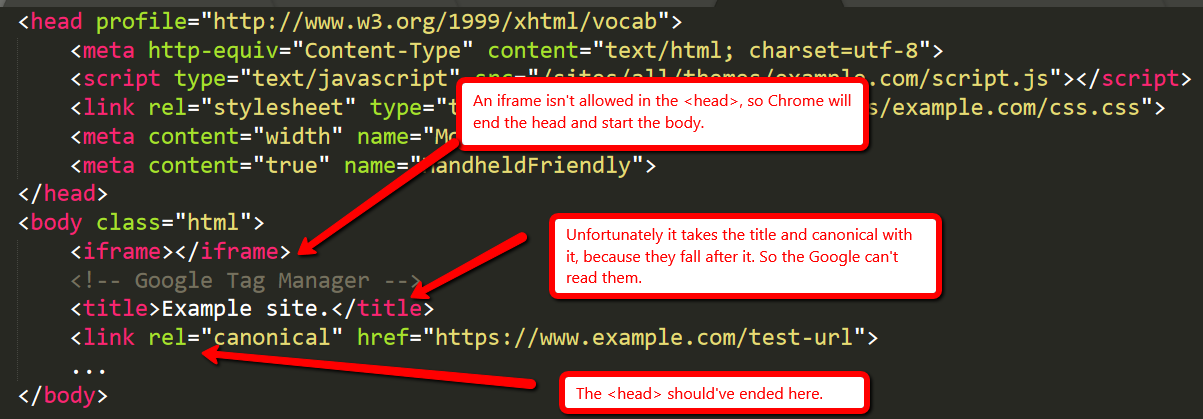
Um iframe não é permitido no código de cabeça, para o Chrome irá terminar a cabeça e começar a corpo. Infelizmente, leva o título e a canonical com ele, porque eles caem depois — para que o Google não consegue ler-los. O código de cabeça deveria ter terminado em um lugar diferente.
Oliver Mason escreveu um bom post que explica de uma forma ainda mais sutil versão deste quebrando a cabeça em silêncio.
Quando em dúvida, diff
Nunca subestime o poder de se tentar comparar duas coisas linha por linha com um ‘diff’ de algo como ‘Diff’, o Verificador. Ele não se aplicar a tudo, mas quando o faz é poderoso.
Por exemplo, se o Google de repente, parou de mostrar o seu destaque de marcação, tenta diff sua página contra uma versão histórica, quer no seu ambiente de QA ou de Wayback Machine.
As respostas para os nossos original 4 perguntas
Tempo para responder a essas perguntas. Estes são todos os problemas que tivemos clientes trazem para nós em água Destilada.
1. Por que não era do Google mostrando, de 5 estrelas, marcação em páginas de produto?
O Google estava vendo o servidor-marcação processada e o lado do cliente-marcação processada; no entanto, o servidor processado lado estava tomando precedência.
Remover o servidor processado marcação significava o 5-estrelas de marcação começaram a aparecer.
2. Por que não Bing display de 5 estrelas marcação na análise de páginas que o Google faria?
O problema veio de referências para schema.org.
Avatar
Diretor: James Cameron (nascido em 16 de agosto de 1954)
ficção científica