Eu sou um auto-financiado pela empresa start-up do proprietário. Como tal, eu quero começar o quanto eu posso grátis antes de convencer o nosso diretor financeiro para gastar o nosso suado de inicialização de fundos. Eu também sou um analista com um plano de dados e ciência da computação, então, um pouco de geek por qualquer definição.
O que eu tento fazer, com a minha analista de SEO de chapéu, é a caça de grandes fontes de dados livres e disputar-lo em algo perspicaz. Por quê? Porque não há nenhum valor em basear cliente conselhos em conjecturas. É muito melhor para combinar dados de qualidade, com uma boa análise e ajudar nossos clientes a entender melhor o que é importante para eles para se concentrar.
Neste artigo, vou dizer-lhe como começar a utilizar alguns recursos gratuitos e ilustrar como reunir exclusivo do google analytics que fornecem informações úteis para o seu blog artigos se você é um escritor, a sua agência se você é um SEO, ou o seu site, se você é um cliente ou proprietário fazer SEO si mesmo.
O cenário que eu vou usar é o que eu quero analisar alguns SEO atributos (e.g. backlinks, Página de Autoridade, etc.) e observar o seu efeito sobre o ranking do Google. Eu quero responder perguntas como “Fazer backlinks realmente importa na obtenção Página 1 de SERPs?” e “Qual o tipo de Página de Autoridade pontuação que eu realmente preciso para estar no top 10 resultados?” Para fazer isso, será preciso combinar dados de diversas pesquisas do Google com dados sobre cada resultado que tem o SEO atributos em que eu deseja medir.
Vamos começar e trabalhar através de como combinar as tarefas a seguir para conseguir isso, que tudo pode ser configurado para livre:
- Consultar com o Google Custom Search Engine
- Usando o livre Moz conta API
- A colheita de dados com PHP e MySQL
- Análise de dados com SQL e R
Consultar com o Google Custom Search Engine
Primeiro precisamos consultar o Google e obter alguns resultados armazenados. Para ficar no lado direito do Google de termos de serviço, nós não vamos ser raspagem Google.com diretamente, mas em vez de usar o Google Pesquisa Personalizada de recurso. Google Pesquisa Personalizada é projetado principalmente para permitir que os proprietários de web site fornecer um Google, como a pesquisa do widget no seu site. No entanto, há também um RESTO com base API de Pesquisa do Google, que é gratuito e permite-lhe consultar o Google e obter resultados no popular formato JSON. Existem limites de cota, mas estes podem ser configurados e estendido para fornecer uma boa amostra de dados para trabalhar.
Quando configurado corretamente para pesquisar em toda a web, você pode enviar consultas para seu Mecanismo de Pesquisa Personalizado, em nosso caso, usando PHP, e tratá-los como o Google respostas, embora com algumas ressalvas. As principais limitações da utilização de um Mecanismo de Pesquisa Personalizado são: (i) não utiliza algumas Google recursos de Pesquisa na Web, tais como os resultados de pesquisa personalizados e; (ii) pode ter um subconjunto de resultados do índice do Google se você incluir mais de dez sites.
Não obstante essas limitações, há muitas opções de pesquisa que podem ser passados para o Mecanismo de Pesquisa Personalizado para o proxy que você pode esperar Google.com para retornar. Em nosso cenário, passamos a seguir ao fazer uma chamada:
https://www.googleapis.com/customsearch/v1?key=&userIp= &cx&q=iPhone+X&cr=countryUS&start= 1
Onde:
- https://www.googleapis.com/customsearch/v1 – é o URL para a Google Pesquisa Personalizada de API
- chave= – O Google Developer Chave da API
- userIp= – O endereço IP da máquina local fazendo a chamada
- cx= – O Google Custom Search Engine ID
- q=iPhone+X – O Google seqüência de caracteres de consulta (‘+’ substitui ‘ ‘)
- cr=countryUS – País de restrição (a partir de Goolge do País de Coleta de Nome na lista)
- iniciar=1 – O índice do primeiro resultado para devolver – e.g. SERP página 1. Sucessivas chamadas de incremento isso para obter páginas 2-5.
O Google disse que o Google Custom Search engine difere do Google .com, mas no meu limitado prod teste de comparação de resultados entre os dois, eu fui encorajado pelo semelhanças e assim continuou com a análise. O que disse, tenha em mente que os dados e os resultados abaixo vir de Pesquisa Personalizado do Google (usando “toda a web” consultas), não Google.com.
Usando o livre Moz conta API
Moz fornecer uma Interface de Programação de Aplicativo (API). Para usá-lo, você precisa registrar-se para uma Mozscape chave de API, que é gratuito, mas limitado a 2.500 linhas por mês e uma consulta a cada dez segundos. Atual pago, planos de dar-lhe o aumento das quotas e começam em us $250/mês. Ter uma conta gratuita e chave de API, você pode, em seguida, consulta a API de Links e analisar os seguintes métricas:
Moz campo de dados
Moz código de API
Descrição
ueid
32
O número externo de capital links para a URL
uid
2048
O número de links (externos, a equidade ou a nonequity ou não) para a URL
umrp**
16384
O Moztrust da URL, como um normalizado 10-contagem de pontos
umrr**
16384
O Moztrust da URL, como um resultado bruto
fmrp**
32768
O Moztrust da URL do subdomínio, como um normalizado 10-contagem de pontos
fmrr**
32768
O Moztrust da URL do subdomínio, como resultado bruto
eua
536870912
O código de status HTTP registados para este URL, se disponível
upa
34359738368
Um normalizada de 100 pontos pontuação representa a probabilidade de uma página para classificar bem nos resultados do mecanismo de pesquisa
pda
68719476736
Um normalizada de 100 pontos pontuação representa a probabilidade de um domínio para classificar bem nos resultados do mecanismo de pesquisa
NOTA: uma vez que esta análise foi capturado, Moz documentado que eles têm preterido esses campos. No entanto, no teste este (15-06-2019), os campos ainda estavam presentes.
Moz API Códigos são adicionados juntos antes de chamar a API de Links com algo que se parece com o seguinte:
www.a apple.com 2F%?Cols=103616137253&AccessID=MOZ_ACCESS_ID& Expires=1560586149&Signature=
Onde:
- http://lsapi.seomoz.com/linkscape/url-metrics/” class=”redator-autoparser-objecto”>http://lsapi.seomoz.com/linksc… – É o URL da API de Moz
- http%3A%2F%2Fwww.a apple.com 2F% – Uma URL codificada que queremos obter dados sobre
- Cols=103616137253 – A quantia de Moz API códigos da tabela acima
- AccessID=MOZ_ACCESS_ID – Uma versão codificada da Moz IDENTIFICAÇÃO de Acesso (encontrado em sua conta API)
- Expira=1560586149 – Um tempo de espera para a consulta de conjunto de alguns minutos para o futuro
- Assinatura= – Uma versão codificada da Moz IDENTIFICAÇÃO de Acesso (encontrado em sua conta API)
Moz vai voltar com algo como o seguinte JSON:
Array ( [ut] => Apple [uu] => www.apple.com/ [ueid] => 13078035 [uid] => 14632963 [uu] => www.apple.com/ [ueid] => 13078035 [uid] => 14632963 [umrp] => 9 [umrr] => 0.8999999762 [fmrp] => 2.602215052 [fmrr] => 0.2602215111 [eua] => 200 [upa] => 90 [pda] => 100 )
Para um excelente ponto de partida consultar Moz com PHP, Perl, Python, Ruby e Javascript, veja este repositório no Github. Eu escolhi para usar o PHP.
A colheita de dados com PHP e MySQL
Agora temos um Motor de Pesquisa Personalizado do Google e a nossa Moz API, nós estamos quase prontos para capturar dados. O Google e Moz responder a pedidos através do formato JSON e, portanto, pode ser consultado por muitas linguagens de programação populares. Além do meu idioma escolhido, PHP, eu escrevi os resultados do Google e Moz para um banco de dados e escolheu o MySQL Community Edition para isso. Outros bancos de dados também pode ser usado, por exemplo, Postgres, Oracle, Microsoft SQL Server, etc. Isso permite a persistência de dados e análise ad-hoc usando o SQL (Structured Query Language), assim como outras línguas (como o R, que eu irei mais tarde). Após a criação de tabelas de banco de dados para armazenar os resultados de pesquisa do Google (com campos para classificação, URL, etc.) e uma tabela para armazenar os Moz campos de dados (ueid, upa, uda etc.), estamos prontos para criar a nossa recolha de dados plano.
O Google fornecer uma generosa quota com o Mecanismo de Pesquisa Personalizado (até 100 m de queries por dia com o mesmo Google console do desenvolvedor chave), mas o Moz API gratuita é limitada a 2.500. Apesar de Moz, pagamento de opções fornecem entre 120k e 40M de linhas por mês, dependendo de planos e variam em custo de us $250–us$10.000/mês. Portanto, como eu estou apenas a explorar a livre opção, eu projetei o meu código para colheita 125 consultas do Google em 2 páginas do SERPs (10 resultados por página), permitindo-me ficar dentro do Moz de 2.500 linha de cota. Como para os quais as pesquisas de fogo no Google, existem inúmeros recursos para uso a partir de. Eu escolhi usar o Mondovo como eles oferecem várias listas por categoria e até 500 palavras por lista, que é amplo para o experimento.
Eu também rolou em alguns PHP classes auxiliares ao lado de meu próprio código para o banco de dados de e/S e HTTP.
Em resumo, as principais PHP blocos de construção e fontes utilizadas foram:
- O Google Custom Search Engine – Ash Kiswany escreveu um excelente artigo usando Jacó Fogg PHP interface para a Pesquisa Personalizada do Google;
- Mozscape API – Como já mencionado, essa PHP implementação para acessar Moz no Github foi um bom ponto de partida;
- Site rastreador e HTTP – No Roxo Toolz, nós temos nossa própria rastreador chamado PurpleToolzBot que usa Curl para HTTP e este Simples HTML Parser DOM;
- Banco de dados de e/S – o PHP tem um excelente suporte para MySQL que eu envolto em classes, a partir desses tutoriais.
Um fator a ser considerado é o de 10 segundos de intervalo entre Moz chamadas de API. Isso é para evitar Moz sendo sobrecarregado por livre API de usuários. Para lidar com esse software, eu escrevi uma “consulta throttler”, que bloqueou o acesso ao Moz API entre chamadas sucessivas dentro de um período de tempo. No entanto, enquanto funcionando perfeitamente, isso significava que chamar Moz 2.500 vezes em sucessão levou 7 horas para ser concluído.
Análise de dados com SQL e R
Dados colhidos. Agora começa a diversão!
É hora de ter um olhar para o que temos. Isso às vezes é chamado de dados de discussão. Eu uso um livre estatística linguagem de programação chamada R, juntamente com um ambiente de desenvolvimento (editor), chamado de R Studio. Existem outras línguas como o Stata e mais gráfica de ciência de dados e de ferramentas como o Tableau, mas estes custos e finanças diretor de Roxo Toolz não é alguém para atravessar!
Tenho estado a utilizar o R para um número de anos, porque é open source e tem muitas bibliotecas de terceiros, tornando-o extremamente versátil e adequado para este tipo de trabalho.
Vamos arregaçar nossas mangas.
Agora, eu tenho um par de tabelas de banco de dados com os resultados da minha 125 termo de pesquisa de consultas em 2 páginas do SERPS (i.e. 20 classificados URLs por termo de pesquisa). Duas tabelas de banco de dados mantenha os resultados do Google e de outra tabela contém o Moz resultados de dados. Para aceder a estas, o que temos de fazer um banco de dados INNER JOIN, que podemos realizar facilmente usando o RMySQL pacote com o R. Este é carregado digitando “install.pacotes(‘RMySQL’)” em R console e inclusive a linha “(biblioteca de RMySQL)” no topo de nossa R script.
Podemos, então, fazer o seguinte para ligar e obter os dados para o R os dados do quadro variável chamada “theResults.”
(biblioteca de RMySQL) # INTERNA JUNTAR as duas tabelas theQuery <- "SELECIONE A.*, B*, C* FROM ( SELECT cseq_search_id DE cse_query ) A — de Pesquisa Personalizado Consulta de ASSOCIAÇÃO INTERNA ( SELECIONE cser_cseq_id, cser_rank, cser_url DE cse_results ) B-Resultados de Pesquisa Personalizada EM A. cseq_search_id = B. cser_cseq_id INNER JOIN ( SELECT * FROM moz ) C-Moz Campos de Dados EM B. cser_url = C. moz_url ;" # [1] Ligar a base de dados # Substituir USER_NAME com o seu nome de usuário de banco de dados # Substitua PASSWORD com a senha do banco de dados # Substituir MY_DB com o seu nome do banco de dados theConn <- dbConnect(dbDriver("MySQL"), o usuário = "USER_NAME", senha = "SENHA", dbname = "MY_DB") # [2] Consulta a banco de dados e armazenar os resultados theResults <- dbGetQuery(theConn, theQuery) # [3] Desconectar do banco de dados dbDisconnect(theConn)
NOTA: eu tenho duas tabelas para armazenar o Google Custom Search Engine dados. Um contém dados sobre o Google consulta (cse_query) e detém um dos resultados (cse_results).
Agora podemos usar R a gama completa de funções estatísticas para começar a discussão.
Vamos começar com alguns resumos para começar uma sensação para os dados. O processo é basicamente o mesmo para cada um dos campos, então vamos ilustrar e usar Moz da ‘UEID’ campo (o número externo de capital links com uma URL). Digitando o seguinte em R recebo a este:
> summary(theResults$moz_ueid) Min. 1st Qu. Mediana Média 3rd Qu. Max. 0 1 20 14709 182 2755274 > gráfico quantil(theResults$moz_ueid, probs = c(1, 5, 10, 25, 50, 75, 80, 90, 95, 99, 100)/100) 1% 5% 10% 25% 50% 75% 80% 90% 95% 99% 100% 0.0 0.0 0.0 1.0 20.0 182.0 337.2 1715.2 7873.4 412283.4 2755274.0
Olhando para isso, você pode ver que a informação é distorcida (e muito) pela relação da mediana para a média, que está sendo puxado pelos valores do quartil superior (faixa de valores acima de 75% das observações). Podemos, no entanto, parcela esta como uma caixa de bigodes em R, onde cada valor de X é a distribuição de UEIDs por classificação, a partir de Pesquisa Personalizado do Google posição 1-20.
Note que estamos usando uma escala logarítmica no eixo y de modo que nós possamos mostrar toda a gama de valores, como eles variam muito!
 Uma caixa e bigodes em R de Moz da UEID pelo Google rank (nota: escala log)
Uma caixa e bigodes em R de Moz da UEID pelo Google rank (nota: escala log)
A caixa e o whiskers parcelas são grandes como eles mostram um monte de informações-los (consulte a geom_boxplot função no R). O roxo área dentro da caixa representa a Inter-Quartil (IQR), que são os valores entre 25% e 75% das observações. A linha horizontal em cada “caixa” que representa o valor da mediana (o do meio quando ordenada), enquanto as linhas, estendendo a partir da caixa (denominado “o whiskers’) representam 1,5 x IQR. Pontos fora o whiskers são chamados de “outliers” e mostrar onde as extensões de cada classe do conjunto de observações. Apesar de a escala logarítmica, pode-se ver um notável pull-up de posição #10 posição #1 em valores da mediana, indicando que o número de participações de links pode ser um Google fator de classificação. Vamos explorar esta mais com densidade de parcelas.
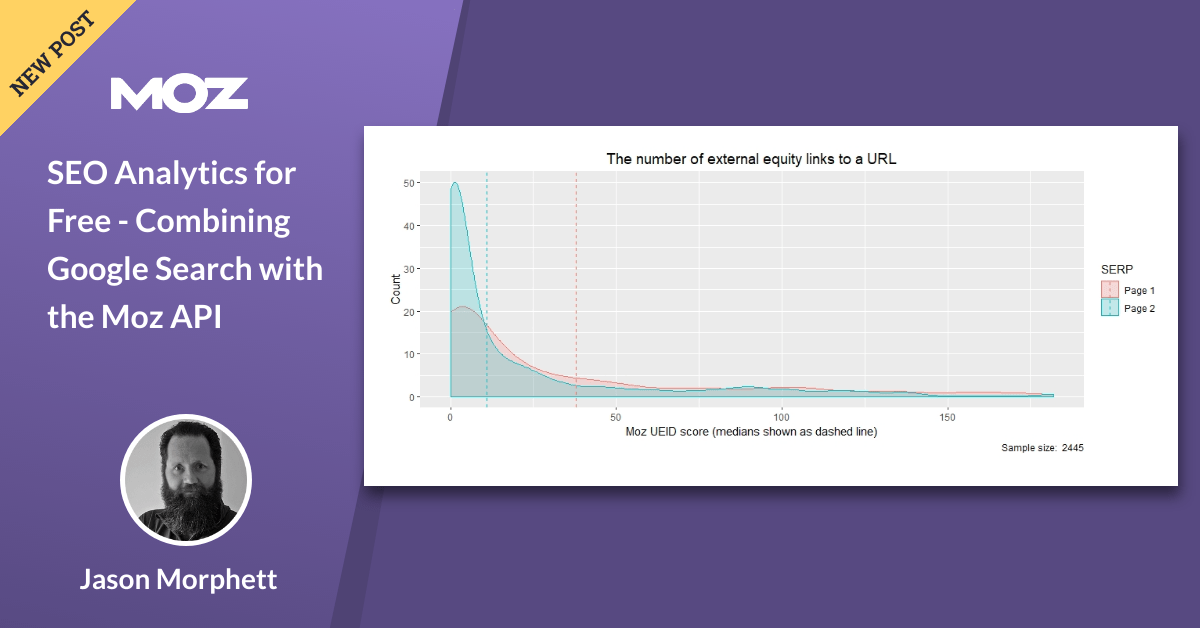
Densidade parcelas são muito parecidos com distribuições (histogramas), mas mostrar linhas suaves em vez de barras para dados. Muito parecido com um histograma, uma densidade enredo do pico mostra onde os valores de dados são concentrados e podem ajudar quando da comparação de duas distribuições. A densidade da trama abaixo, dividimos os dados em duas categorias: (i) os resultados que apareceram na Página 1 de SERPs classificados de 1 a 10 são cor-de-rosa e; (ii) os resultados que apareceram na SERP Página 2 estão em azul. Eu também plotadas as medianas de ambas as distribuições, para ajudar a ilustrar a diferença de resultados entre a Página 1 e Página 2.

A inferência a partir desses dois densidade de parcelas é que a Página 1 resultados SERP tinha mais externos de capital backlinks (UEIDs) em que Página 2 de resultados. Você também pode ver os valores da mediana para essas duas categorias abaixo, que mostra claramente como o valor para a Página 1 (38) é muito maior do que a Página 2 (11). Então agora temos alguns números para a base de nossa estratégia de SEO para seus backlinks de no.
# Crie um fator R de acordo com o que SERP página de resultado (cser_rank) está em > theResults$rankBin theResults$rankBin tapply(theResults$moz_ueid, theResults$rankBin, mediana) Página 1 Página 2 38 11
A partir disso, podemos deduzir que o patrimônio backlinks (UEID) a matéria e se eu fosse aconselhar um cliente com base nesses dados, eu diria que eles devem estar olhando para obter mais de 38 baseados na equidade backlinks para ajudá-los a chegar à Página 1 de SERPs. Este é, claro, uma amostra limitada e mais pesquisa, uma amostra de maior dimensão e de outros fatores de ranking precisa ser considerado, mas você começa a idéia.
Agora vamos investigar outra métrica que tem menos de um intervalo em que UEID e olhar Moz da UPA medida, que é a probabilidade de que uma página irá classificar bem nos resultados do mecanismo de pesquisa.
> summary(theResults$moz_upa) Min. 1st Qu. Mediana Média 3rd Qu. Max. 1.00 de 33,00 41.00 41.22 50.00 de 81,00 > gráfico quantil(theResults$moz_upa, probs = c(1, 5, 10, 25, 50, 75, 80, 90, 95, 99, 100)/100) 1% 5% 10% 25% 50% 75% 80% 90% 95% 99% 100% 12 20 25 33 41 50 53 58 62 75 81
UPA é um número dado a um URL, e varia entre 0 a 100. Os dados são melhor comportado do que o anterior UEID unbounded variable ter a sua média e a mediana juntos para fazer mais ‘normal’ de distribuição, como podemos ver abaixo, por desenhar um histograma em R.
 Um histograma de Moz da UPA pontuação
Um histograma de Moz da UPA pontuação
Nós vamos fazer a mesma Página 1 Página 2 de divisão e a densidade da trama que fizemos antes e olhar para a UPA pontuação distribuições de quando dividimos a UPA de dados em dois grupos.
 # Relatório, as medianas por SERP página chamando ‘tapply’ > tapply(theResults$moz_upa, theResults$rankBin, mediana) Página 1 Página 2 de 43 39
# Relatório, as medianas por SERP página chamando ‘tapply’ > tapply(theResults$moz_upa, theResults$rankBin, mediana) Página 1 Página 2 de 43 39
Em resumo, duas formas muito diferentes distribuições de duas Moz API variáveis. Mas ambos mostraram diferenças nas suas pontuações entre SERP páginas e fornecer-lhe com valores concretos (medianas) para trabalhar com e, em última análise, assessoria a clientes em ou aplicar para o seu próprio SEO.
Claro, essa é apenas uma pequena amostra e não deve ser tomada literalmente. Mas com recursos gratuitos da Google e Moz, agora você pode ver como você pode começar a desenvolver as capacidades analíticas de sua própria base de seus pressupostos, em vez de aceitar a norma. Ranking de SEO fatores mudam o tempo todo e ter suas próprias ferramentas analíticas para conduzir seus próprios testes e experimentos sobre o vai ajudar a dar-lhe credibilidade e, talvez, até mesmo uma única visão sobre algo até então desconhecido.
O Google fornecer-lhe com um saudável cota livre para obter os resultados da pesquisa. Se você precisa de mais de 2.500 linhas/mês Moz fornecer gratuitamente existem inúmeras pagos, de planos que você pode comprar. O MySQL é um download gratuito e R é também um pacote gratuito para a análise estatística (e muito mais).
Ir para explorar!

![How to Get Your Web Developer on Board with SEO [Bonus PDF] Whiteboard Friday](https://oximarketingdigital.com.br/wp-content/uploads/2020/02/how-to-get-your-web-developer-on-board-with-seo-bonus-pdf-whiteboard-friday.png)



