
Marieke van de Rakt
Marieke van de Rakt é o fundador da Yoast SEO Academia e CEO da Yoast. O seu favorito SEO tópicos são de SEO copywriting e estrutura do site.

Ranking nos motores de busca requer um website com impecável técnica de SEO. Felizmente, o Yoast SEO plugin cuida de (quase) tudo sobre o seu site WordPress. Ainda assim, se você realmente deseja obter o máximo de seu site e manter a outranking a competição, alguns conhecimentos básicos de técnicas de SEO é uma obrigação. Neste post, vou explicar um dos conceitos mais importantes da técnica de SEO: crawlability.
O que é o rastreador de novo?
Um motor de busca, como o Google consiste de um rastreador, um índice, e um algoritmo. O rastreador segue os links. Quando o Google rastreador encontra o seu site, ele vai ler e o seu conteúdo é salvo no índice.
Um rastreador segue os links na web. Um rastreador é também chamado de um robô, um robô, ou uma aranha. Ele vai volta internet 24/7. Uma vez que se trata de um site, ele salva a versão HTML de uma página em um gigantesco banco de dados, chamado de índice. Este índice é atualizado cada vez que o rastreador que vem em torno de seu website e encontra um novo ou revisado versão do mesmo. Dependendo de como é importante o Google considerar o seu site e o número de alterações que você fizer em seu site, o rastreador vem com mais ou menos frequência.
Leia mais: noções básicas de SEO: o que o Google faz “
E o que é crawlability?
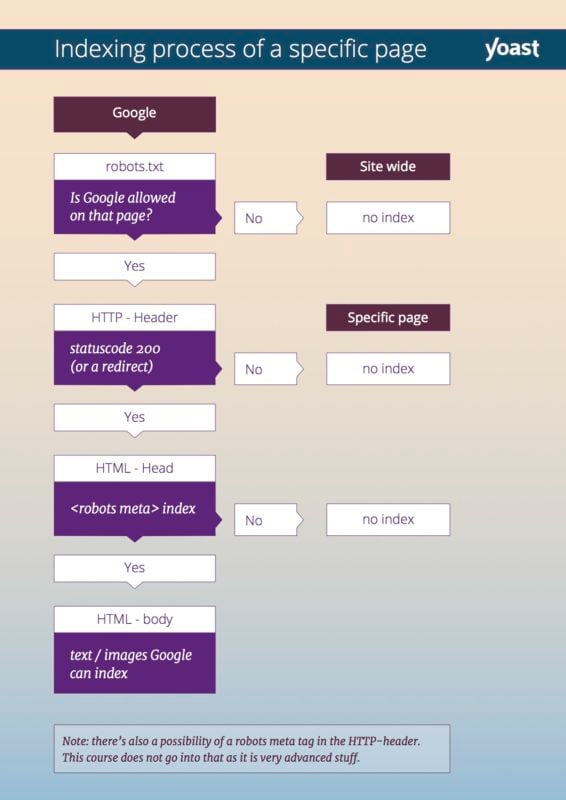
Crawlability tem a ver com as possibilidades que o Google tem para rastrear o seu site. Os indexadores podem ser bloqueados a partir do seu site. Existem algumas maneiras de bloquear um rastreador a partir de seu site. Se o seu website ou para uma página do seu site é bloqueado, você está dizendo ao Google rastreador: “não venham aqui”. O seu site ou a respectiva página, não transformar-se em resultados de pesquisa na maioria dos casos. Existem algumas coisas que podem impedir o Google de rastreamento (ou indexação) de seu site:
- Se o seu robots.txt blocos de arquivo o rastreador, o Google não vai vir para o seu site ou página da web específica.
- Antes de indexar o seu web site, o rastreador irá dar uma olhada no cabeçalho HTTP da página. Este cabeçalho HTTP contém um código de status. Se esse código de status diz que a página não existe, o Google não irá rastrear o seu site. No módulo sobre cabeçalhos HTTP de nossas Técnicas de SEO training nós vamos dizer-lhe tudo sobre isso.
- Se a meta tag robots em uma página específica bloqueia o motor de busca de indexar a página, o Google irá rastrear a página, mas não adicioná-lo ao seu índice.
Este fluxograma pode ajudar você a entender o processo de bots seguir ao tentar indexar uma página:
Quer aprender tudo sobre crawlability?
Embora crawlability é apenas o básico de técnicas de SEO (que tem a ver com todas as coisas que ativar o Google de indexar o seu site), para a maioria das pessoas já é bastante avançados. No entanto, se você está bloqueando – talvez até mesmo sem saber! – rastreadores de seu site, você nunca vai ter uma boa classificação no Google. Então, se você é sério sobre SEO, essa deve ser uma questão para você.
Se você realmente quer entender todos os aspectos técnicos relativos crawlability, você deve definitivamente verificar para fora a nossa Técnica de formação de SEO. Neste SEO curso, vamos ensinar-lhe como detectar técnicas de SEO problemas e como resolvê-los (com o nosso Yoast SEO plugin).
Continue lendo: o Que é a técnica SEO: 8 aspectos que todos deveriam saber “

![How to Get Your Web Developer on Board with SEO [Bonus PDF] Whiteboard Friday](https://oximarketingdigital.com.br/wp-content/uploads/2020/02/how-to-get-your-web-developer-on-board-with-seo-bonus-pdf-whiteboard-friday.png)



